Prompt Engineering
My Best Attempt at Explaining Prompt Engineering

Caveat: Prompt Engineering is a relatively new (and therefore immature) field. Unlike established computer science fields, standards here are fluid & young. If you’re reading this and thinking “this seems…untested / amateurish…” (because prompting is basically “instructing / explicating intent clearly”), then, well - you’re not alone.
What is Prompt Engineering?
Prompt Engineering is the strategic discipline of structuring natural language inputs to program the behavior of Large Language Models (LLMs) without updating their underlying root model weights.

It’s important to distinguish Prompt Engineering from Context Engineering:
Context Engineering is the Fuel or Accelerant. It is the architectural management of the information environment (RAG pipelines, vector databases, retrieved knowledge) that the model can access.
Prompt Engineering is the Ignition or Catalyst. It is the specific constraint-logic and instructional design that sparks that fuel into accurate, coherent, and safe output.
The “Stochastic” Reality
LLMs & AI systems rely upon Neural Networks, massive vector databases wherein “semantic wisdom,” is derived from calculating functions to convey meaning between words and concepts.

In the illustrations below we are conveying these relationships visually, just know the vector gradients inside of AI systems are far more complicated & multidimensional (indeed, even superposition concepts apply here).

However, despite the over-simplification, the visual three dimensional (vs. multidimensional) abstraction can help you to understand what happens when an LLM’s pre-training knowledge base can help AI to infer concepts, taxonomies, ideas, relationships, systems, and complex logic.

Ever used Auto-Correct, or auto-complete (yes it’s horrible on iPhone, still) on your Phone’s keyboard?
That’s essentially a very, very, very simple version of what LLMs chatbots like ChatGPT, Claude, or Gemini.
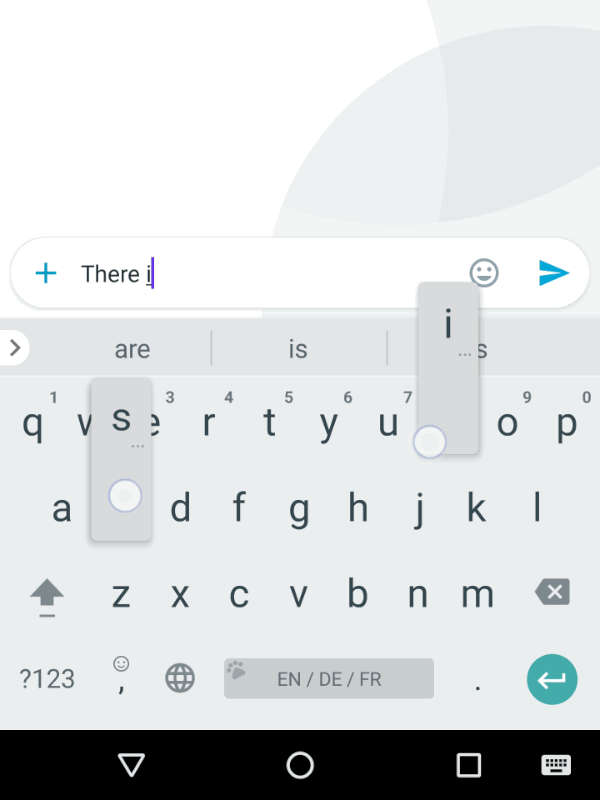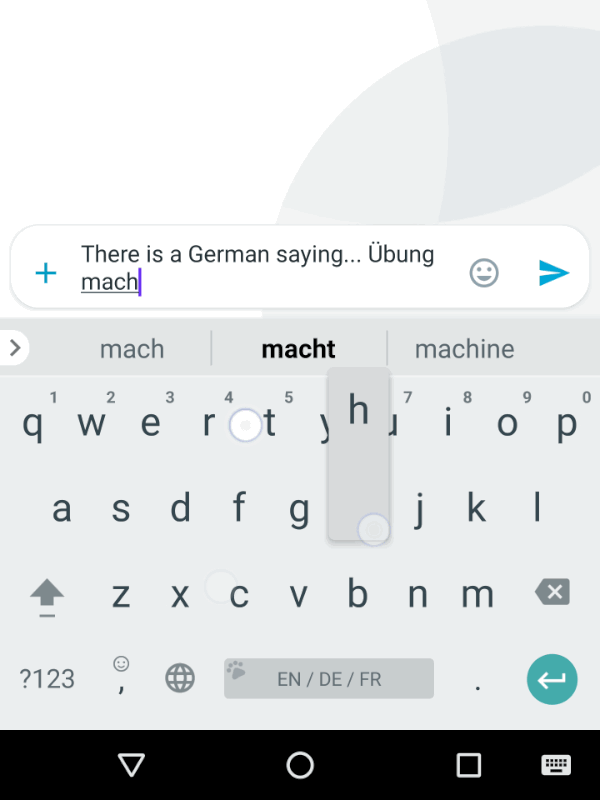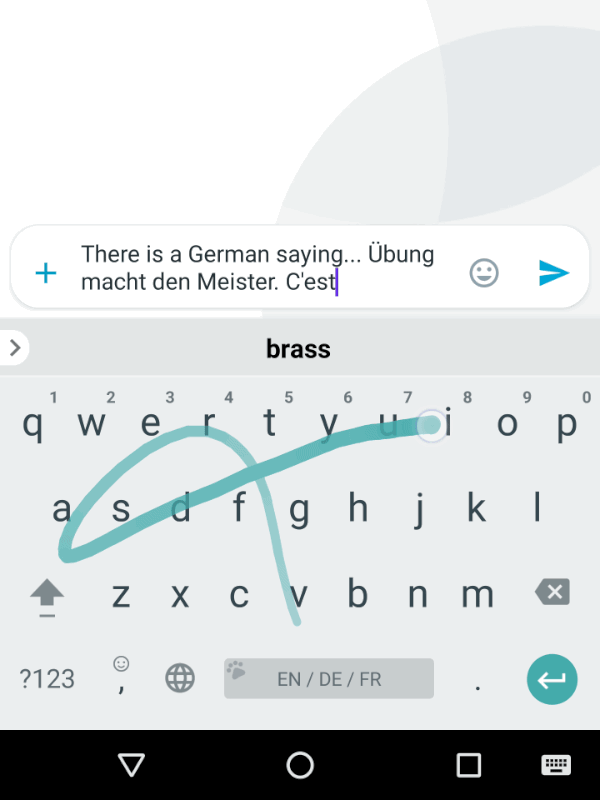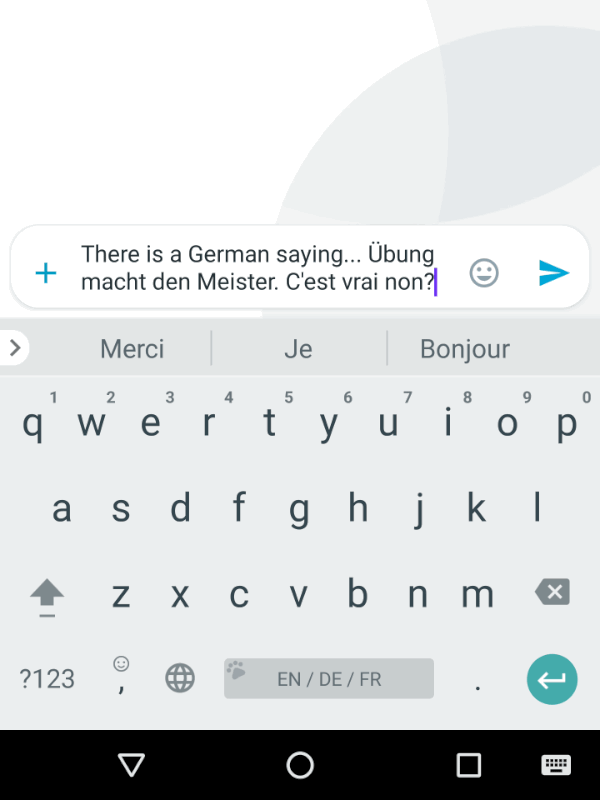
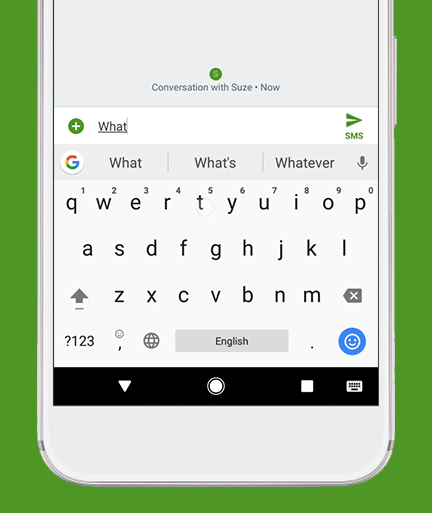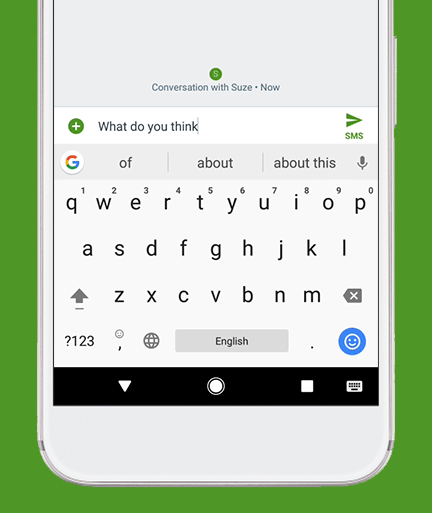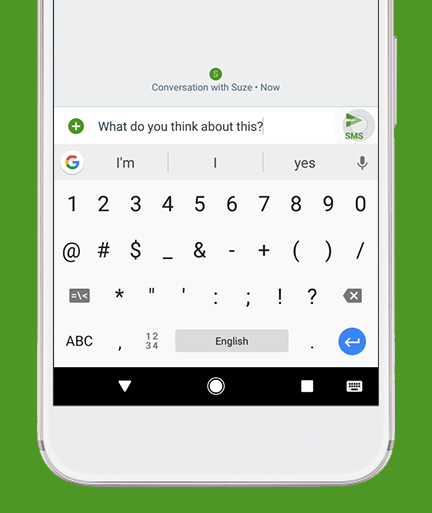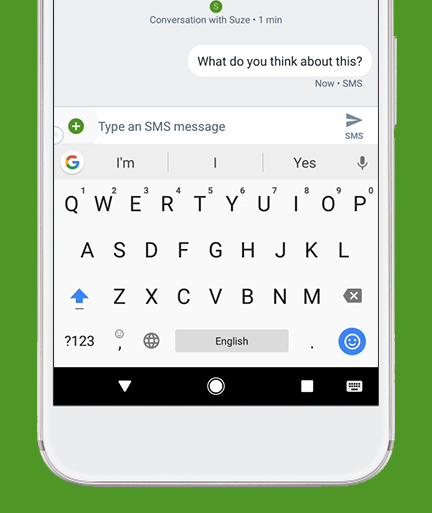
You can see this same type of “Stochastic” prediction that LLMs are executing in realtime on your phone.
Open up your Phone’s keyboard app & try to activate the “next word” interface (where you just pick the next word from 2-3 that it suggests).
That predictive program, running on your Phone (even without an internet connection, running on your phone’s hardware), is simply doing it’s best to derive what you’re intending to say / talk about next based on the CONTEXT: your proceeding words (it’s more complicated than this, but you get the idea).
With LLMs, instead of predicting the next word in a sentence, models are trying to predict the next sentence, paragraph, etc. based on a given Prompt.
When you send ChatGPT, Gemini, or Claude a prompt of any kind, those LLMs are using very similar algorithms (just far more complex, far bigger ones) as your phone keyboard’s predictive algorithms to construct far more complex “outputs,” (usually chats, or documents or code).

Fundamentally these systems are just using what came before (the prompt, context) to predict what ought to be generated next.

Each word inside of an LLM’s base model is “tokenized,” - assigned a numeric value:

This means that we can essentially just “math,” the difference between King and Queen :

We can see that baseline algebra concepts (i.e. if you know A + B = C but only know B & C, you can derive A’s value) to understand / unpack that semantic wisdom can be conveyed in mathematical formulas: King - Man = Queen and Queen - Woman = King, etc.; see: Take and Took, Gaggle and Goose, Book and Read: Evaluating the...

